

Scalable web applications
A scalable web application can handle growth – of users or work – without requiring changes to the source code.
The following are some guidelines that I’ve gathered for designing scalable web applications regardless of the programming language that you use. They have proven useful to lots of companies including Twitter, Github and LinkedIn just to name a few. Although it is not an exhaustive list, I hope you find them interesting and valuable ;)
Keep the architecture simple
Divide your application into smaller applications (modules) that share nothing. Treat everything else as an external service. For example, the following image shows a web module, a worker module and some shared external services.
The web module handles HTTP requests while the worker module executes background jobs (e.g. gathering statistics, generating reports, etc.). It’s a simple but powerful way of thinking about your application. Each module is completely independent of each other. They could even be written in different languages!
Modules use external services to communicate with each other (e.g. a database, a message queue, etc.). This interesting post, for example, shows how Github uses an external service called Resque to trigger and execute background jobs.
Each module is executed as one or more processes —in one or more servers. For instance, you could have two running processes of your web module and four running processes of your worker module as shown in the image below. Although not shown, each process could be running on a different server. We will talk about the clock process in the following section.
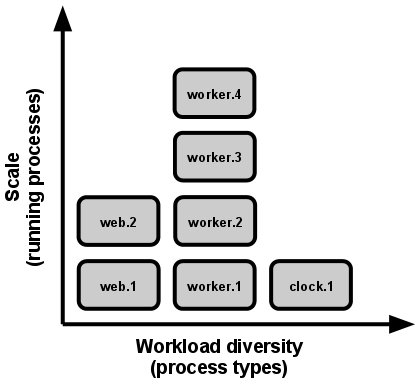
If you want to learn more about how modern web applications are designed and built, I recommend you check out this site from which I took the image above. The only oddity is that they use the expression process type for what I refer here as a module1.
Scheduling
If your application needs to support task scheduling there are two approaches that you can use. The first is to use a cloud service such as Heroku Scheduler, IronWorker or similar. The other is to create your own scheduling solution --or use an existing one-- and execute it in a single process.
If you go with the second approach, try not to execute the tasks in the same scheduler process; instead, use the worker processes for that. The scheduler process should be responsible of triggering the tasks, not executing them.
The file system and memory space
Never use the file system or the memory space of a process to save data that needs to be persisted longer than a single transaction/request.
The following should be obvious but it is worth saying: if you save a file in the process’ file system, it won’t be visible to other processes (on different servers). Use a service such as Amazon S3 or a shared file system instead.
The same applies to the memory space. For example, if a module writes a variable (e.g. a primitive value, a collection, an object, etc.) and there are multiple processes of that module running, each process will have it’s own value of the variable. Use Redis, Memcached or a similar external service instead if you need to share the value of the variable.
You can still use the file system and the memory space for operations that span a single transaction or request, and for files and variables that don’t need to be persisted or shared.
Beware of libraries and frameworks
Some libraries and frameworks will use the process’ file system or the memory space to write data that should be persisted and shared among processes.
For example, most web frameworks, by default, store session data2 in the process’ memory space. This is ok if there’s only one process running. However, with multiple processes, and depending of what you store in the session, the application could start behaving erronously3.
Another example is a library that uses the memory space to cache some expensive calculation. That cache won’t be so useful because each process will have to do the calculation anyway4.
As you can see, the consequences can range from a loss in performance to a misbehaving application. Few libraries explicitly document this so most of the time you’ll just have to guess.
Conclusion
A simple architecture and some additional considerations is all you need to build a scalable web application. Sure, your external services need to scale as well. But having a scalable architecture will allow you iterate and focus on one problem at a time. Nothing worst than having to redesign the whole architecture during a growth burst.
1 It is easier to think about the web module than the web process type when building your project.
2 This is a place used to store transient information about user that is currently using your application.
3 The solution, in this case, is to use a different session storage mechanism such as Redis or Memcached (most web frameworks support this feature).
4 The solution is to write that value to and external service such as Redis or Memcached.